





INTRODUCTION
In November 2022, OpenAI launched the ChatGPT service based on a generative language model (GLM) called GPT.1 This is an important milestone in the development of artificial intelligence (AI) technology, which has brought about major changes in natural language processing and computer science.1,2 GLM-based services such as ChatGPT use machine learning algorithms to mimic and generate the language that people understand and use.1,3 These GLM-based services can perform a variety of tasks, including text generation, question answering, and sentence completion.1,3
GLMs, such as OpenAI’s GPT, Google’s BERT, and Meta’s Llama, are currently being actively developed and have influenced many fields such as economy, industry, and medicine.4-6 It is used in information search, customer service, and education, and its impact continues to expand.7,8 These GLMs can perform a variety of tasks, including generating text, answering questions, and completing sentences.9 The diversity and efficiency of tasks these models can perform depend largely on the amount of information that the models can process and generate based on the data used for training.10
However, GLMs are not perfect and still need to be improved. GLMs in service currently cover general knowledge but lack knowledge of specialized domains.11,12 This means that the model may have difficulty answering specialized questions accurately.11,12 Additionally, these models often fail to provide complete and accurate answers to users’ questions.13,14 There is a representative problem called ‘hallucination’, which refers to a phenomenon in which the model generates information that is not in the training data or provides incorrect information.15,16 These issues reduce model reliability and can provide incorrect information to users.15,16
To solve these problems, there is a need for GLMs tuned to specialized domains. Especially in the medical field, since accurate and reliable information is important, the need for GLMs that include medical information is becoming more and more prominent.4,12,17,18 These models should be able to provide medical knowledge to people other than medical experts.4,19 These models can also play an important role in efficiently supporting the training of healthcare professionals.4,20,21 In particular, it can help students in medical professions understand complex medical terms, basis for medical guidance, and determine appropriate treatment plans for various patient situations.20-22
The purpose of this study was to provide empirical evidence on the benefits of domain-specific fine-tuning of language models, demonstrating that such models not only improve accuracy in the specialized domain of musculoskeletal diagnosis and treatment but also highlight the potential for these models to serve as educational tools and decision-support systems in clinical settings. Therefore, this study compared the answers generated when questions related to the specialized musculoskeletal domain of physical therapy were applied to fine-tuned and untuned models, respectively, to evaluate and confirm the possibility of whether language models fine-tuned to the professional domain can correctly answer professional knowledge.
METHODS
The process of collecting, processing, and fine-tuning the data to the language model is shown in Figure 1. For this study, books related to the diagnosis and treatment of musculoskeletal disorders in the field of physical therapy were selected. First, the book ‘Functional Anatomy’, which is considered the most basic area in diagnosing or treating musculoskeletal disorders, was selected.23 And a book called ‘Kinesiology’, which describes the movement of the musculoskeletal system in the human body, was selected.24 In addition, ‘Diagnosis and Treatment of Movement System Impairment Syndromes’, ‘Muscle Imbalance’, and ‘Kinetic Control’ books, in which diagnostic theories using movement or musculoskeletal systems were written in relation to musculoskeletal disorders, were selected.25-27 Finally, a book called “Therapeutic Exercise,” which describes exercise therapy, one of the options for treating musculoskeletal disorders, was selected.28 Document text was extracted using the RecursiveCharacterTextSplitter, and large chapters of the document were divided into small units to increase processing efficiency. The extracted text was embedded by HuggingFaceInstructorEmbedding. The embedded document was then converted into a database format using Chroma to enable saving and retrieval.
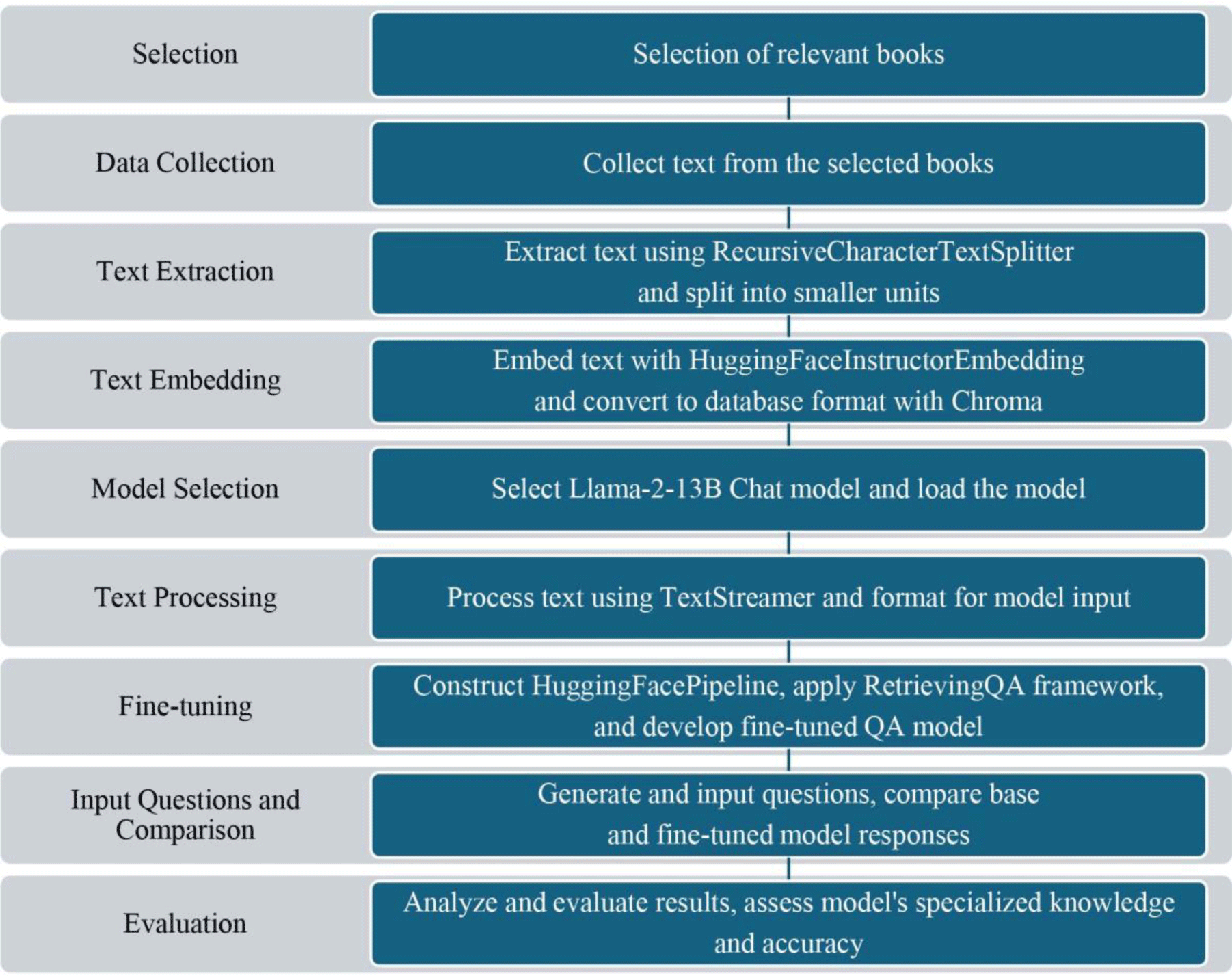
The Llama-2-13B Chat model was selected and fine-tuned using a dataset comprising approximately 1.2 million tokens extracted from the chosen textbooks. The fine-tuning process involved training for 1 epoch, with a learning rate of 2e-4 and a batch size of 4. These hyperparameters were optimized based on preliminary experiments to ensure the model’s performance in specialized tasks. This model is specifically designed for interactive AI and question-answering scenarios. The Lama-2-13B model was loaded using the AutoGPTQForCausalLM library, and the settings required for model fine-tuning were performed. TextStreamer, a component that processes input text, was used to process text data effectively. This step was important in preparing and formatting the input text before feeding it to the model. The process of creating a response using the Lama-2-13B model by constructing the HuggingFacePipeline has been simplified. This pipeline has been applied to generate consistent and contextually relevant responses by managing various aspects such as tokenization and decoding during the creation process. Finally, the RetrivingQA framework was used to develop a QA model with added search functionality. Through this process, a Fine-tuned QA model was established, which is expected to provide more accurate and contextual responses to various musculoskeletal disease diagnosis and treatment-related questions.
Questions were selected based on key topics and frequent inquiries encountered in physical therapy practice, as identified from the selected books. The selection process involved consultations with experts in the field to ensure that the questions reflect real-world clinical scenarios. This approach aimed to test the model’s ability to respond accurately to common and critical issues within the musculoskeletal domain. The questions created were entered into the base and fine-tuned models, respectively. The questions created and entered according to the selected books were as shown in Table 1.
RESULTS
The answers generated for each question of the base and the fine-tuned models are presented in Table 2. The base model often failed to understand or provide relevant information because the questions were unclear or key terms were not recognized. In contrast, the fine-tuned model consistently produced answers specific to the musculoskeletal context, demonstrating improved understanding of specialized topics. In particular, the fine-tuned model did not show any lack of information for any question and showed improved performance in processing musculoskeletal inquiries based on fine-tuned text content. Regarding the serratus anterior muscle, the base model provided a general over-view of its role in shoulder movement and stabilization. In contrast, the fine-tuned model provided a more detailed description, emphasizing specific movements during arm lifting and outcomes related to muscle paralysis. For the scapulo-humeral rhythm, the base model was insufficient to provide information due to lack of context, but the fine-tuned model provided a comprehensive definition, including details on the “set-up phase” and the constant rate of humerus and scapula movement during shoulder flexion. Regarding scapular downward rotation syndrome, the base model was unfamiliar and additional information was requested. In contrast, the fine-tuned model not only defined the major movement disorders but also outlined the associated muscle dysfunction, symptoms, and available treatment options. In the case of upper crossed syndrome, the base model acknowledged ignorance of the term and suggested that more context was needed. Conversely, the fine-tuned model identified specific muscle tension and weakness patterns associated with the syndrome, providing a detailed description. Regarding the kinetic medial rotation test, the base model lacked information about the test and provided speculative guesses based on the phrases provided. In contrast, the fine-tuned model describes the components of the test in more detail and explains how the results contribute to assessing rotator cuff muscles. Regarding postoperative management of the glenohumeral joint, the base model provides general postoperative management principles, emphasizing the need for individualized advice. On the other hand, fine-tuned models represent a more nuanced understanding, emphasizing the importance of early mobilization, exercise, and potentially surgical stabilization for specific cases.
DISCUSSION
The base model generally provided accurate information, but it lacked detailed information about certain terms or concepts. However, general information was provided on postoperative management of the glenohumeral joint. The fine-tuned model provided more detailed and specialized information on specific terms and concepts. It may provide more contextual information, but there may be differences in the quality of the response. It was suggested that fine-tuned models tend to provide more detailed and context-specific answers, especially in areas related to specific muscle activities, syndromes, and tests. For serratus anterior, scapula-humeral rhythm, scapular inferior rotation syndrome, superior crossed syndrome, and kinetic medial rotation test, fine-tuned model provided in-depth insights, whereas base model often provided uninformed or speculative guesses. Overall, the fine-tuned model demonstrated superior performance, demonstrating its ability to provide more detailed and contextual information across a variety of musculoskeletal topics compared to the base model, which provides general information.
These results were consistent with various studies showing that model tuning enables effective and expert responses to questions by equipping models with specific knowledge of specialized domains.6,11,14 Several studies have already attempted to fine-tune large-scale language models or build medical language models in the medical field.19,29,30 Yang et al.29 introduced a large-scale clinical language model called GatorTron, developed with more than 9 billion words of text, and the generative model using this language model led to the improvement of medical question answers.29 Additionally, Lu et al.30 introduced the ClinicalT5 model and said that this model can be applied to various tasks in the medical field because it can understand and process medical terminology, context, and special language structures.30 Nova19 suggested that using a GLM learned from text data such as medical records or from medical personnel’s voice data could simplify and provide medical information that was difficult for patients to understand.19
Development of a language model in a specific field such as the above or improvement of the model through fine-tuning is also used for education in that field.8,11,21 Karabacak et al.21 suggested that AI and GLMs will provide significant opportunities to improve medical education through realistic simulations, digital patients, personalized feedback, assessment methods, and removal of language barriers.21 Unlike previous studies that used medical records, this study used text data from books containing knowledge about the musculoskeletal system in the field of physical therapy to fine-tune the model, but it is expected to be helpful in education as well. This is an important advancement that could provide a new dimension in expanding medical education and expertise. This approach is expected to contain specific knowledge about the field and provide more detailed information, allowing medical professionals and educators to provide learners more effectively with an in-depth understanding of specific topics. The expertise gained through fine-tuning the model not only increases its applicability in clinical situations, but also provides learners with rich experience of real-world situations in the field. This realistic training environment can improve the practical skills of healthcare professionals and increase the effectiveness of research-based training. Additionally, the utilization of GLM can overcome language barriers and improve the quality of global medical education. Able to understand and handle multiple languages and cultures, GLM can foster international educational collaboration and improve information exchange between healthcare professionals.
However, several problems are being raised in content creation using AI and GLM. Among them are content quality, bias, and ethical and legal issues.21 In addition, it is required to develop guidelines and policies in evaluating the accuracy of AI-generated content.20,21 To this end, it is said that reliability and reliability can be increased by sharing information on data and evaluation methods used in education.21 Continuous research and academic cooperation are needed to realize the maximum potential of AI and GLM in medical education and to respond to potential risks and challenges at the same time.21 It is said that through the cooperation of medical experts, these technologies will be integrated in an effective and responsible way, leading to improved medical care between learning experiences and patients.20,21
There are several limitations to this study. Firstly, the study focused exclusively on text data from books related to musculoskeletal diagnosis and treatment, which may limit the model’s exposure to a wide range of medical conditions and patient cases. It could result in the model providing less generalizable or comprehensive answers outside the specific domain of physical therapy. Secondly, this study did not use quantitative metrics such as accuracy and precision to evaluate the performance of the fine-tuned model. While the qualitative analysis indicates that the fine-tuned model offers more contextually relevant and specialized answers, the lack of statistical evaluation limits the ability to objectively measure and compare its performance against the base model. Future studies should include these quantitative assessments to provide a more rigorous and objective evaluation of model improvements. Additionally, the selected textbooks may introduce bias based on their specific medical approaches, potentially affecting the model’s responses. Lastly, relying solely on textbook information for fine-tuning may not capture the most up-to-date or empirically validated knowledge, potentially limiting the model’s effectiveness in reflecting current clinical practices. To address these limitations, future studies should include a more diverse dataset that encompasses a broader range of medical conditions and patient cases to improve the model’s generalizability. Furthermore, in future studies, it will be essential to validate the performance using quantitative metrics to evaluate and compare the performance of fine-tuned and underlying models. Additionally, future research should explore the inclusion of real-world clinical data and recent research articles in the fine-tuning process to ensure that the model remains current and reflective of empirical knowledge. Finally, investigating the model’s performance on non-specialized and broader medical questions will provide insights into its versatility and potential applications beyond the initial scope of this study.
CONCLUSION
The model fine-tuned with books on musculoskeletal diagnosis and treatment showed superior performance in providing various information related to the topic compared to the basic model. This demonstrates the effectiveness of model tuning for a specific knowledge domain and suggests that model enhancement using textual data on the musculoskeletal system may help in medical education and expertise acquisition. However, there will be a need for guidelines and policies to evaluate reliable AI-generated content, and there will be a need to increase reliability by sharing information on data and evaluation methods used in education.